
TL;DR – Storage costs often rise dramatically as a company grows and develops. When data volumes grow after a product’s introduction, it can sometimes be difficult to understand what data is useful and what can be safely removed. A company that does not clean its data often may pay 20 percent more than necessary because of unused data.
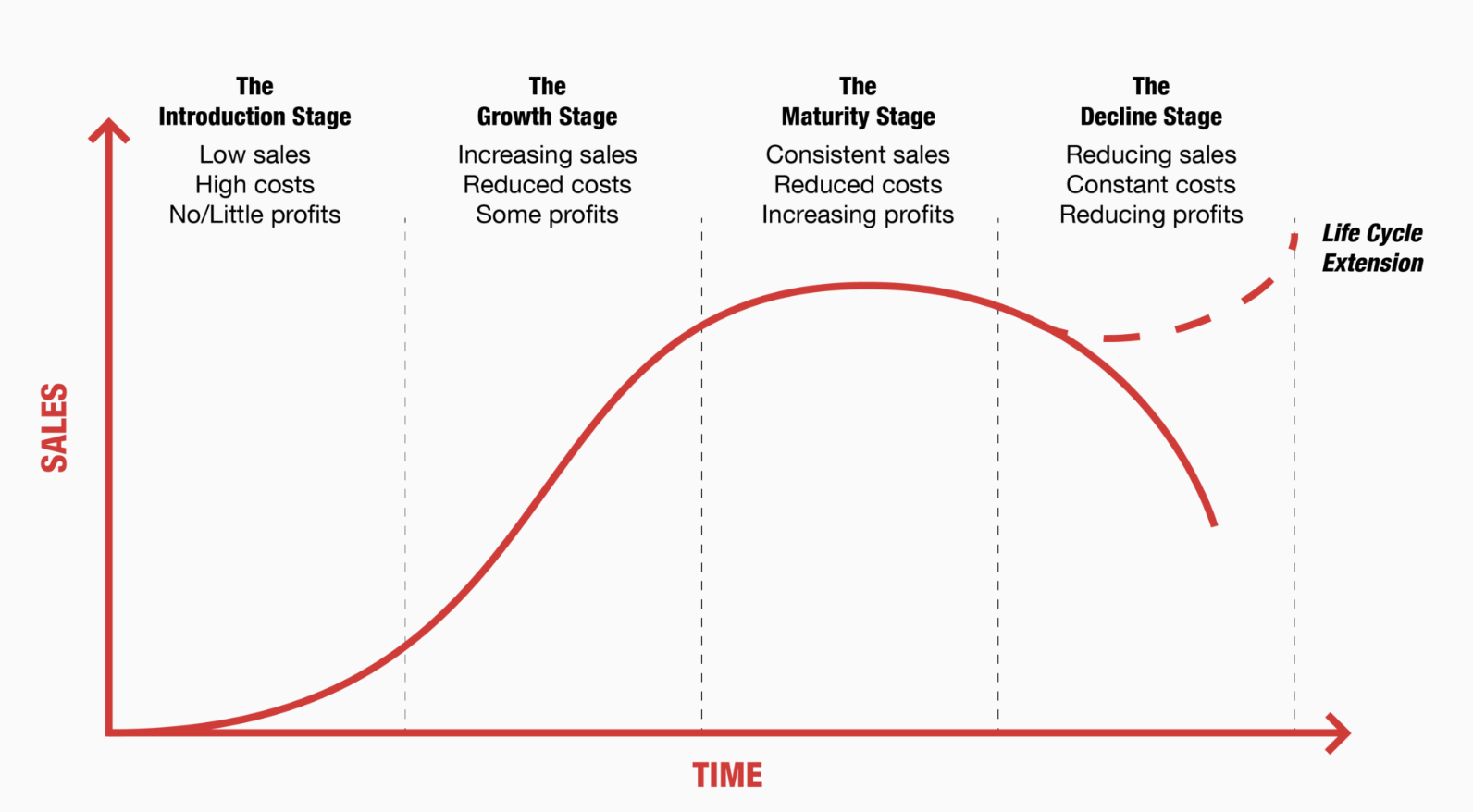
Traditional company lifecycle models begin with a period of rapid growth with the majority of the focus on customer acquisition, rather than on data sustainability.
Data is collected, modified, and saved directly into a database, usually without taking into account how much storage is needed to accommodate it.
The result of this “move fast” perspective can be unusable stored data, to the tune of 20% of total storage costs that could’ve been avoided. Extrapolated out over years, this can cause data-intensive organizations to spend millions of dollars more than necessary to store something useless to them.
There are numerous articles available about how to reduce the cost of stored data. These articles almost exclusively focus on architecture and network communications challenges (transactions, network connectivity improvements, centralized storage, and software-defined storage approaches), but they don’t often look at the data itself.
To solve a similar problem we faced at HUMAN, we sought a solution that would reduce the costs of the data itself, assuming the architecture and network communications aspects would also be reduced.
In a recent HUMAN hackathon, our team decided to tackle this issue. We wanted to have two outputs as a result of this effort:
- Identify unused tables that may be deleted.
- Identify unused columns within used tables to review if we can make use of their data or delete them.
Since we were dealing with tons of data, we had to think of an efficient way to process it. Therefore, we chose to use the BigQuery log table, which contains the metadata of our tables. By using this method, we could inspect many tables and columns faster than we could by looking at each one individually.
We extracted the following from the logs data:
- A timestamp (the time the query was executed)
- Table names
- Column names
We divided our findings into three buckets:
- Last used within the previous 3 months
- Last used between 3-6 months ago
- Last used more than 6 months ago
The following day, we made the decision to delete one of these tables, which resulted in an annual savings of around $40K. Encouraged by this success, we continued our review and were able to delete several more tables, resulting in a total savings of around $90K annually thus far.
We’ve created an automated process that runs these queries once a month and updates a dedicated dashboard. By doing so, we believe that one year from now, we will have our database aligned in the most efficient way. We also created an open-source repository for this project with instructions that everyone who uses BigQuery can examine – and start spending less on data storage. To sum up, our efforts managed to cut costs by pinpointing specific, low-use areas in the corners of our data storage. About 20% of our tabular data was initially reviewed, and costs were immediately reduced afterward.
On to the next hackathon!
Hackathon team: Noy Wolfson – SE, Or Mazza – SE, Lauren Saraby – FinOps, Shaked Chen – Researcher, Guy Raviv – Product Analyst