
The devops industry has increasingly embraced infrastructure as a code (IaC) over the past few years. Managing your infrastructure in such a way has multiple benefits, such as keeping a history of your infrastructure changes, allowing quick rollbacks and allowing peer review.
There are plenty of tools out there to achieve this goal, such as Terraform, Crossplane, Pulumi and more.In this article, we will focus on how to manage your resources with dependencies and constraints. We use Pulumi to manage our cloud resources, but the principle is the same for all IaC tools.
What is a Pulumi stack?
According to Pulumi documentation, “Pulumi stack is an isolated, independently configurable instance of a Pulumi program.” The cloud resources of each stack are saved in their own state file.
When we change the configuration or the code and apply the change (pulumi up command), Pulumi will compare the new state that was created by the configuration and code with the current saved state.
Pulumi commands run against a specific stack, so if changes are made, all resources in that stack could potentially be affected.
The Current Project
In every Pulumi project, one of the more consequential questions to answer is how it could be separated into different stacks. This topic is mentioned in the pulumi documentation here.The common options are
- Monolithic – each stack represents a gcp project
- Micro-stacks – each network resource (network resource is combined by multiple cloud resources) should be in its own stack.
Monolith is simple at first. But, as the code, functionality or the amount of cloud resources increases, it becomes more complex and difficult to maintain. The monolith approach is a good way to start your journey with Pulumi, but when you have a lot of cloud resources, micro stacks are a better solution.
Micro stacks vs Monolithic
To better understand these approaches, assume we are managing the network layer in GCP in a monolith approach. In this approach, dozens of Google load balancers and other network components will be managed in one stack. The risks are:
- Every change can potentially change another resource in the stack, so each change should be handled with extra care.
- Having all the resources in one place makes it difficult to understand what is connected to what, and what resources are no longer used.
We decided to look at micro-stacks instead of monoliths to prevent these risks. The micro stack approach can be implemented in many ways. In our case, we decided that each load balancer will have its own stack.
In this way, we can be confident that the scope of the change is a single load balancer and that the change will not affect other load balancers.
The two main things we have to address in this approach is the dependency between shared resources and the ability to run one Pulumi command against multiple load balancers.
Bypassing the Limitations
Using the pulumi automation API, we created a light CLI tool that wraps the Pulumi commands.As shown below, each stack (load balancer) is represented in the configuration file:
hello-world_load_balancer.yaml
backend_services<span>:</span><br><span>-</span> name<span>:</span> hello<span>-</span>world<span>-</span>service<br> load_balancing_scheme<span>:</span> <span>EXTERNAL</span><br> health_checks<span>:</span> hello<span>-</span>world<span>-</span>health<span>-</span>check<br> backends<span>:</span><br> <span>-</span> max_utilization<span>:</span> <span>0.8</span><br> name<span>:</span> hello<span>-</span>world<span>-</span>mig<br> zone<span>:</span> europe<span>-</span>west1<span>-</span>b<br>health_checks<span>:</span> <span>[</span><span>]</span><br>http_load_balancers<span>:</span><br><span>-</span> name<span>:</span> hello<span>-</span>world<span>-</span>load<span>-</span>balancer<br> urlmap<span>:</span><br> default_backend<span>:</span> hello<span>-</span>world<span>-</span>service<br> frontends<span>:</span><br> https<span>:</span><br> ip_port<span>:</span><br> <span>-</span> port<span>:</span> <span>443</span><br> ip_name<span>:</span> hello<span>-</span>world<span>-</span>ip<br> ssl_certificates<span>:</span><br> default_certificate<span>:</span> perimeterx<span>-</span>com<br>depends_on<span>:</span><br><span>-</span> common<span>-</span>healthcheckcommon_healthcheck.yaml
health_checks<span>:</span><br><span>-</span> name<span>:</span> common<span>-</span>health<span>-</span>check<br> http_health_check<span>:</span><br> request_path<span>:</span> <span>/</span>alive<br> port<span>:</span> <span>9095</span>In this example, common_healthcheck.yaml is defining a common health check that is being used by different backend services. There is dependency between the two stacks because the backend service uses a health check that is not defined in its own file.
A dependency list is obtained by the depends_on attribute in each configuration file.
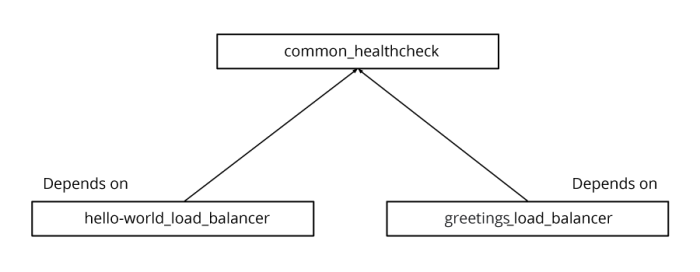
The CLI tool gets the configuration files as arguments and reads their dependencies.
In the case of multiple layers of dependency, the CLI will create a graph of all the dependencies, validate they are not circular and execute them in the correct order.As a result, if changes occur in both stacks that depend on each other, the tool will run them both in the correct order.
The communication between the stacks is performed using pulumi outputs.
This CLI tool is addressing the parallel operation against multiple stacks.
By getting a list of stacks, building the dependency graph as mentioned above, and running the pulumi commands simultaneously, we can run horizontal changes quickly as a built-in functionally.
Code snippets
-
Pseudo code of the main flow
def func <span>pulumi_up</span><span>(</span>stack_files<span>)</span><span>:</span><br> graph <span>=</span> <span>build_dependecy_graphs</span><span>(</span>stacks_file<span>)</span><br> # seperate into steps<br> # each step contains multiple stacks<br> # the stacks <span>in</span> the step can run <span>in</span> parallel<br> # steps should run <span>in</span> the right order<br> steps <span>=</span> <span>seperate_into_steps</span><span>(</span>graph<span>)</span><br> executor <span>=</span> <span>ThreadPoolExecutor</span><span>(</span>thread_size<span>)</span><br> <span>for</span> step <span>in</span> steps<span>:</span><br> <span>for</span> stack <span>in</span> step<span>:</span><br> stack <span>=</span> pulumi_api<span>.</span><span>select_stack</span><span>(</span>stack<span>)</span><br> executor<span>.</span><span>submit</span><span>(</span>lambda<span>:</span> stack<span>.</span><span>up</span><span>(</span><span>)</span><span>)</span> -
Handling the dependency using networkx
def <span>build_dependency_graph</span><span>(</span>self<span>,</span> current_stack<span>)</span><span>:</span><br> <span>if</span> not self<span>.</span><span>is_gen_empty</span><span>(</span>nx<span>.</span><span>simple_cycles</span><span>(</span>self<span>.</span>graph<span>)</span><span>)</span><span>:</span><br> logging<span>.</span><span>error</span><span>(</span><span>'there is dependency cycle, exiting'</span><span>)</span><br> <span>exit</span><span>(</span><span>1</span><span>)</span><br> self<span>.</span>graph<span>.</span><span>add_node</span><span>(</span>current_stack<span>)</span><br> config <span>=</span> self<span>.</span><span>read_yaml</span><span>(</span>current_stack<span>)</span><br> <span>if</span> <span>'depends_on'</span> <span>in</span> config<span>:</span><br> <span>for</span> dependency_stack <span>in</span> config<span>[</span><span>'depends_on'</span><span>]</span><span>:</span><br> self<span>.</span>graph<span>.</span><span>add_edge</span><span>(</span>dependency_stack<span>,</span> current_stack<span>)</span><br> self<span>.</span><span>build_dependency_graph</span><span>(</span>dependency_stack<span>)</span> -
Create steps from the graph
def <span>create_steps</span><span>(</span>self<span>)</span><span>:</span><br> copied_graph <span>=</span> self<span>.</span>graph<span>.</span><span>copy</span><span>(</span><span>)</span><br> steps <span>=</span> <span>[</span><span>]</span><br> <span>while</span> copied_graph<span>:</span><br> zero_indegree <span>=</span> <span>[</span>v <span>for</span> v<span>,</span> d <span>in</span> copied_graph<span>.</span><span>in_degree</span><span>(</span><span>)</span> <span>if</span> d <span>==</span> <span>0</span><span>]</span><br> steps<span>.</span><span>append</span><span>(</span>zero_indegree<span>)</span><br> copied_graph<span>.</span><span>remove_nodes_from</span><span>(</span>zero_indegree<span>)</span><br> <span>return</span> steps
Summary
From our experience, moving to a micro-stack approach is just a question of time. With the principles above, this transition can be much easier and smoother than previously assumed.