
Artificial intelligence has introduced a new category of automated traffic, generated by an expanding mix of tools: scrapers and crawlers feeding large language models, retrieval bots dispatched mid-conversation, AI browsers that simulate human navigation, and full agent systems that plan and act across many steps. It’s a remarkable shift, bringing new capabilities and possibilities for users and businesses alike, but it also creates a more complex landscape to manage and secure.
With new categories come new words, and here the industry often falls short. Commentators, marketers, and even some security vendors use terms like “AI chatbot,” “LLM crawler,” and “AI agent” as though they’re interchangeable. They aren’t. Each class behaves differently and presents different challenges for the companies that need to manage their traffic.
Lumping them together obscures both risk and value and steers security teams toward blunt controls that miss the point.
First Principles: Not Every “AI bot” is Intelligent
Let’s start with the confusing part: there is nothing inherently “AI” about how most so-called “AI crawlers” or “AI scrapers” operate. Their novelty is their purpose, not their mechanics.
Technically, they look just like classic automation that discovers pages or extracts text at scale. The difference is that they gather content for AI systems, either to train models or to retrieve context on demand for users. So we can treat them as automation for AI, not AI in itself.
Agentic systems are the opposite end of the spectrum. They plan, decide, and act with a goal in mind, often stringing together browsing, code execution, and API calls. They can complete multi-step, stateful tasks that look like a human session and not a single “hit.” OpenAI describes agents that operate a visual browser, a text browser, a terminal, and direct API access in one integrated loop. That capability is precisely why they demand different scrutiny and controls.

The Foundation: Large Language Models (LLMs)
Before examining specific types of AI-powered traffic, we need to understand the technological foundation that enables most of these sophisticated systems: Large Language Models. Large Language Models process and generate human language through deep learning architectures trained on vast amounts of text data. These systems develop a statistical understanding of language patterns, context, and meaning that enables them to generate coherent, contextually appropriate responses to novel inputs.
How LLMs Enable Sophisticated Traffic Patterns
LLMs serve as the reasoning layer that transforms simple automation into intelligent, adaptive systems, but the actual web traffic comes from applications and frameworks that leverage LLM capabilities.
In AI scraping and crawling operations, LLMs are the ultimate destination for collected data rather than the system directing the collection. Companies like OpenAI, Anthropic, and others deploy specialized crawlers like GPTBot and ClaudeBot to gather the massive text datasets needed to train their language models.
In RAG (Retrieval Augmented Generation) systems, LLMs function as processing engines that understand user queries, interpret retrieved information, and synthesize coherent responses. When you ask a RAG-powered system about current events, the LLM recognizes that your question requires recent information beyond its training data. Then the RAG architecture—the application framework surrounding the LLM—triggers specialized retrieval systems to gather current information.
For AI agents and agentic browsers, LLMs serve as the reasoning and planning components that enable autonomous decision-making. When you instruct an AI agent to “research OpenAI’s latest features and book a demo,” the LLM understands your instruction, breaks it down into logical steps, interprets the results of each step, and plans subsequent actions. However, the actual web interactions—form submissions, API calls, navigation sequences—are executed by the agent framework that surrounds and utilizes the LLM. The agent framework translates the LLM’s reasoning into concrete web actions, maintains session state, handles errors, and manages the complex workflows that appear in your traffic logs.
Understanding the Core Categories of AI Traffic
LLM Crawlers and Scrapers: Data Harvesters
LLMs require truly massive amounts of text data for training. While some of this training data comes from established public datasets, many AI providers need to supplement these sources with fresh, targeted content collection. This is where AI scrapers enter the picture. Unlike traditional web crawlers that might collect pages for search indexing, AI scrapers are specifically designed to gather high-quality content that will improve language model capabilities.
The Transparency Challenge
Here’s where the situation becomes more complex for trust and security teams: these declared, identifiable scrapers represent only the visible portion of AI-driven data collection.
Many AI companies likely rely on third-party data aggregation services or operate secondary, undeclared crawlers that attempt to bypass detection and restrictions.
This reality creates a significant challenge for both bot detection and content governance strategies. If your detection system relies primarily on user agent strings or IP reputation alone, you’ll successfully identify and manage the cooperative crawlers while potentially missing stealthier operations that deliberately avoid identification.
LLM Crawler Examples
Several major AI companies operate dedicated crawlers and provide clear documentation about their use, making them relatively easy to identify in your traffic logs.
GPTBot operates as OpenAI’s primary web crawler, explicitly designed to retrieve public content for potential use in model training. Its complete user agent string appears as:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbotThis crawler demonstrates what we might call “well-behaved” scraping practices. It respects robots.txt directives, maintains reasonable request rates to avoid overwhelming servers, and focuses on broad content collection across diverse websites to improve ChatGPT’s knowledge base. OpenAI provides documentation, including published IP ranges, for all of its crawler bots.
ClaudeBot serves the same function for Anthropic, systematically collecting content to enhance Claude’s training data. Its user agent follows a nearly identical format:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; [email protected])
The similarity in user agent structure reflects industry conventions that make these systems easier to identify and manage through standard web server configurations.
PerplexityBot presents an interesting case study because Perplexity doesn’t actually train its own foundation models. Instead, this crawler supports Perplexity’s AI-driven search engine by building and maintaining a comprehensive web index. Perplexity provides documentation, including published IP ranges, for all of its crawler bots.
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Should You Block LLM Crawlers?
That depends on your business goals. Managing AI scrapers ultimately represents a policy choice rather than a purely technical security decision. Blocking known scrapers like GPTBot or ClaudeBot ensures your content won’t be used directly in model training, which may align with privacy objectives or monetization strategies. However, this decision also means your brand, expertise, and content might not surface in future AI-generated outputs, potentially reducing your visibility as AI-powered search and assistance tools become more prevalent.
HUMAN’s approach to controlling AI-driven content scraping provides sophisticated policy management that goes beyond simple allow/block decisions, enabling organizations to make nuanced choices about different types of AI-driven data collection based on their specific business objectives and risk tolerance. For example, you may allow a scraper to learn from marketing content, but disallow scraping of product pricing pages. It is even possible to charge scrapers a small fee to access valuable content via our integration with TollBit.
RAG Systems: Knowledge Enhancers
Retrieval Augmented Generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal knowledge base.
RAG systems work through a two-phase process: retrieval and generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In the generative phase, the LLM draws from the augmented prompt and its internal representation to synthesize an engaging answer tailored to the user.
Unlike scrapers that collect data for future use, RAG systems operate on demand in response to specific user queries. When someone asks ChatGPT about current events or requests real-time information, the system recognizes that its training data alone cannot provide an accurate answer. Instead, it deploys specialized retrieval bots to fetch current information from authoritative sources, then incorporates this fresh data into its response.

RAG Scraper Examples
ChatGPT-User is deployed when ChatGPT searches the web during conversations, it performs RAG operations by retrieving current information and incorporating it into responses.
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/botClaude-User – Anthropic’s equivalent retrieval agent that appears when Claude needs to fetch content to fulfill user requests. While less documented than OpenAI’s implementation, it serves the same function of bridging the gap between static training data and dynamic information needs. Anthropic’s documentation claims that Claude-User respects robots.txt, but it has not published a full UA string.
Perplexity-User When users ask Perplexity a question, it might visit a web page to help provide an accurate answer and include a link to the page in its response. Perplexity-User controls which sites these user requests can access.
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user)
Should You Block RAG Scrapers?
RAG systems present a more nuanced risk profile than traditional scrapers because they operate on behalf of real users seeking specific information. Outright blocking this traffic could disrupt AI functionality and prevent your content from reaching AI users.
At the same time, there can be legitimate reasons to manage this traffic. One significant concern involves content attribution and citation practices. While some RAG systems, like Perplexity’s, provide clear citations that can drive traffic back to your site, others may extract and summarize your content without providing meaningful attribution or traffic referral. This creates a potential scenario where your expertise and insights reach audiences through AI-generated responses without corresponding brand recognition or website visits.
AI Agents and Browsers: Autonomous Actors
AI agents are the most sophisticated and potentially transformative category of automated traffic. These are AI systems designed to operate with a degree of autonomy, making decisions, taking actions, and adapting in real-time without continual human oversight.
As drivers of agentic commerce, agents represent significant potential business value, but they also present the most complex risk profile of all AI traffic categories. The fundamental risk lies in their ability to execute sensitive operations like account creation, login processes, transaction completion, and data modification. We have even observed AI agents solving CAPTCHA when attempting to carry out tasks! However, as demonstrated below, they were not able to solve the HUMAN Challenge.
When legitimate agents perform these actions on behalf of authorized users, they provide value by automating tedious tasks and enabling new forms of digital assistance. But these same capabilities make them powerful tools for malicious actors seeking to automate fraud, account takeover attempts, or transaction abuse.
Detecting AI Agents
Detecting AI agents poses significant detection challenges due to both their operating models and their behavior.
Cloud-based agents, like OpenAI’s Operator, use shared IP infrastructure, making traditional IP reputation and geographic analysis ineffective.
Local agents operate within user browsers, inheriting the same fingerprints, session states, and network characteristics as legitimate manual activity.
Finally, AI agents performing legitimate tasks may exhibit all the technical markers that security systems associate with malicious automation, including rapid form completion, consistent timing patterns, programmatic navigation flows, and systematic interaction sequences. Traditional heuristics that flag these behaviors as suspicious may now be blocking legitimate user-delegated automation.
However, HUMAN’s research teams have invested heavily in building visibility into AI agent activity. Today, AgenticTrust and HUMAN Sightline provide comprehensive visibility into AI agent operations, enabling organizations to understand and govern agent behavior rather than simply block it. You can learn about some of our published detection signals and methodologies in our detailed analysis of AI agent traffic signals.
Verification for AI Agents
The industry is moving toward cryptographic verification as the solution for reliable AI agent identification. This approach allows agents to prove their identity and legitimate delegation through cryptographic signatures rather than relying on easily spoofed identifiers. OpenAI has embraced this approach with ChatGPT agent authentication, implementing HTTP Message Signatures (RFC 9421) that enable websites to cryptographically verify agent authenticity through signature validation.
At HUMAN, we’ve been early advocates and contributors to this standards development, releasing the HUMAN Verified AI Agent demonstration as an open-source foundation for cryptographically authenticated AI agent communication. Our team has contributed to OWASP’s guidance on agentic applications, helping establish industry standards for secure agent verification and governance.
AI Agent Examples:
ChatGPT Agent is OpenAI’s agent, which can autonomously interact with websites, fill forms, make purchases, and complete complex workflows on behalf of users. It operates using its own virtual computer and can take actions like clicking buttons, entering text, and navigating between pages to accomplish user-defined goals. The system requests user permission before taking sensitive actions like authentication or payment processes. ChatGPT Agent can be cryptographically verified through signature validation.
Claude Computer Use is Anthropic’s agentic capability, available through its API, that enables Claude to autonomously interact with desktop environments and applications. It can perceive the screen, move the cursor, click buttons, enter text, and navigate interfaces to complete multi-step workflows on behalf of users.
Agentic Browser Examples:
Perplexity Comet Perplexity’s dedicated agentic browser built for “agentic search.” Currently in beta for select Mac users, Comet can autonomously execute complex tasks like booking flights, managing reservations, and handling multi-step workflows. It features deep research integration, real-time information processing with source citations, and extensive app integrations covering over 800 applications. Comet personalizes responses based on browsing history and open tabs while keeping data stored locally, making its traffic patterns nearly identical to manual user activity. Comet presents standard Chromium signatures, often indistinguishable from regular browser traffic. AgenticTrust is capable of detecting and managing Comet traffic.
Claude for Chrome is Anthropic’s forthcoming Chrome extension that integrates Claude’s AI capabilities directly into the browser experience. Unlike standalone agentic browsers, Claude for Chrome operates as a browser extension, allowing users to interact with Claude while browsing any website. The extension can read page content, help with tasks like writing and analysis, and assist with web-based workflows while maintaining the standard Chrome browser environment.
Browser Use Framework – A popular open-source framework that enables AI agents to interact with websites autonomously using standard browser automation techniques. It allows developers to create agents that can navigate complex web workflows programmatically while appearing as legitimate browser traffic.
Should You Block AI Agents?
In most cases, no. Most agents visit websites on behalf of human users, so blocking them essentially blocks those users from completing their tasks. If that task was to make a purchase, the agent will quickly move to another site, and you’ve effectively blocked a potential sale.
Instead, we recommend verifying agent identity and employing thoughtful governance over their allowed actions. HUMAN’s AgenticTrust enables organizations to move beyond binary blocking decisions toward adaptive governance that can distinguish between beneficial automation and potential threats based on behavior, context, and verified identity rather than simple presence detection.
Looking Forward: The Agentic Internet
We’re facing a new class of adversaries and a new class of allies at the same time. Success in the agentic era will depend on the ability to verify and trust automated agents, not simply block them.
As this ecosystem continues to evolve, organizations that thrive will move beyond simple blocking strategies to embrace sophisticated governance approaches that can adapt to the nuanced reality of AI-powered interactions.
That’s why we built AgenticTrust, a new module in HUMAN Sightline Cyberfraud Defense, built to give you visibility, control, and adaptive governance over agent-based activity in your websites, applications, and mobile apps.
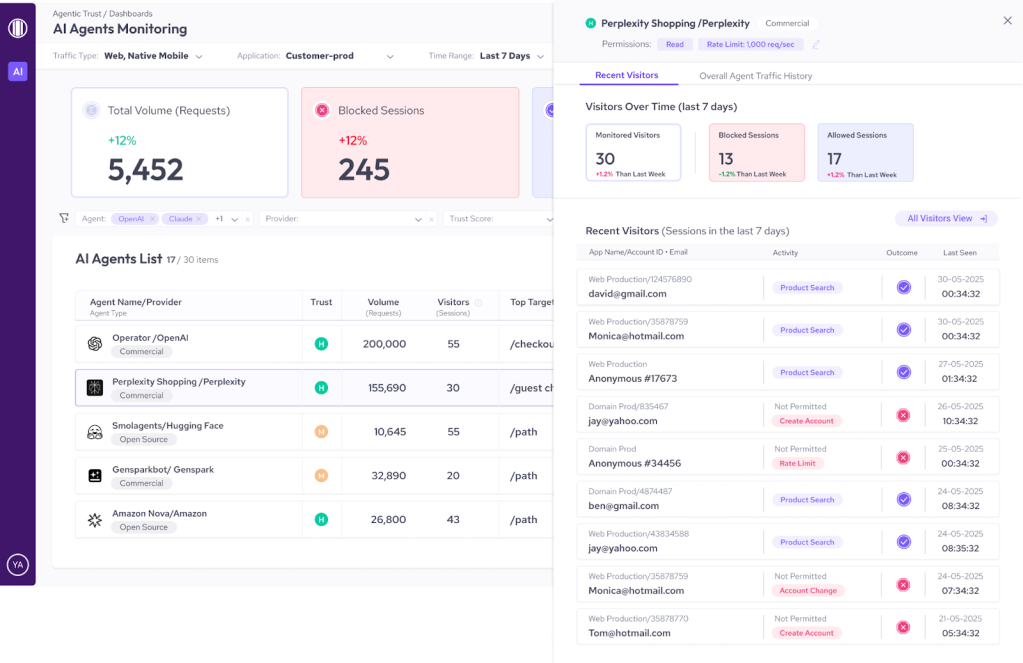
AgenticTrust gives security and fraud teams continuous visibility into the AI agents interacting with their websites and applications. It identifies agents, classifies their behavior, and enforces rules that govern what agents are allowed to do and what they’re not, so you can allow agentic commerce responsibly.
Ready to govern AI agents, scrapers, and automated traffic with precision and confidence? Discover how AgenticTrust provides the visibility, control, and adaptive governance you need to safely enable agentic commerce while protecting against abuse across your entire customer journey. Request a demo today.
Get visibility and control over AI agents and agentic browsers on your website.
