
You know that you spend a lot of money on the cloud. How much of that spend is necessary? And can you improve the efficiency of your spend? These are questions affecting every team and company running cloud workloads. The global economy is slowing due to the pandemic. Cutting fat is critical to keeping companies profitable or, in worst cases, afloat.
As a fast-growing startup, HUMAN (where I work) began thinking about FinOps several years back when we realized that our infrastructure spend was a black box that could significantly affect our business – both positively and negatively. Everyone in DevOps has read about (and possibly lived through) the horror story of a massive surprise cloud bill because of a dev team mistake or someone forgetting to shut down a sizeable temporary cluster or an emergency response to a scaling event was not unwound in a timely fashion. The goal of FinOps is to prevent these types of disasters by allowing teams managing cloud infrastructure to analyze and interrogate their spend and test hypotheses about the interplay between cloud services.
The big surprise? Diving into the FinOps challenge opened our eyes to how an outstanding FinOps practice can not only save money but also lead to better customer experience and smarter product design.
What Is FinOps?
For many readers, this may be a new concept. The definition from the FinOps Foundation covers it nicely:
“FinOps is the operating model for the cloud. FinOps enables a shift — a combination of systems, best practices, and culture — to increase an organization’s ability to understand cloud costs and make tradeoffs. In the same way that DevOps revolutionized development by breaking down silos and increasing agility, FinOps increases the business value of cloud by bringing together technology, business, and finance professionals with a new set of processes.”
Simply put, FinOps applies the same principles of DevOps to financial and operational management of cloud assets and infrastructure. Ideally, this means managing those assets through code rather than human interventions. To do this effectively, a FinOps practitioner must understand the patterns of both customer usage and product requirements, and map those correctly to maximize value while continuing to optimize for customer experience.
How We Started Our FinOps Journey At HUMAN
We started by asking, “Why are we doing this?”. One reason was to improve margins and better manage our cloud spend. But we realized that we could use FinOps to create a clear vision of our infrastructure philosophy and bridge the communication gap between our Dev, DevOps, and Finance teams. The main issues we were seeing and wanted to resolve were:
- Our Dev teams did not always consider the financial implications of their architectural decisions
- Aligning our DevOps team’s cost optimization goals and new product capabilities was challenging
- Finance teams were using 1-to-2-month-old invoice data to inform management teams of spend, making decision making, and identification of elevated spend areas harder
- Communication between Dev, DevOps, and Finance teams on upcoming and ongoing spend was often slow and ineffective
We thought adopting a FinOps program and mindset could put our teams on the same page, align their points of view, and provide a shared framework of tracked metrics for day-to-day decision-making processes.
FinOps In Action At HUMAN
HUMAN is a SaaS security company that helps companies defend their web applications, mobile apps, and APIs against malicious bots and skimming attacks like Magecart. Our business operations and some engineering are in Silicon Valley, and the majority of our development team is in Israel.
Our journey started three years ago as an effort to better understand, measure, and manage our cloud spend. We knew as we grew that optimizing our cloud spend could have a material impact on our gross margins. Our FinOps effort started as an internal R&D project to create tooling for cloud spend management and measurement that also linked closely to application usage and performance – even down to individual customers. HUMAN has multiple internal teams that use cloud infrastructure, and the company often builds internal products to meet custom needs. The engineering team, which falls under the R&D team, is the unit that builds these products. The engineering team also researches and develops new features. Once a feature is slated to go into the product roadmap and production, the engineering team takes over development.
When we started our FinOps project, all we had to work with were flat data files that lacked key information. With these flat files, we had no easy means of attributing dollar values to specific projects or research deployments. Needless to say, this was a nightmare. To create a starting point, we manually enriched a lot of the data with approximations and back-of-the-envelope estimates of our cloud spending patterns. While the numbers were not accurate (to say the least), the goals we had in mind have remained the same ever since:
- Create and maintain a budget for allocating R&D and tracking monthly spend for research, staging, and other R&D cloud spending (excluding spend on production deployments and sales and marketing functions)
- Build a model of how much each new product feature might cost depending on key variables like traffic served and customer location
From Flat Files to Granular Cloud Service Tracking: FinOps Takes Flight
We got a huge break when Google Cloud rolled out a more detailed billing itemization export capability that could pipe directly into BigQuery, their analytical database. This capability ushered in an Age of Enlightenment for our FinOps efforts, thanks to the rich and granular data we could now pull in automatically from our GCP usage data.
For operational measurement reasons, we had already put in place granular labeling of each subsystem and service in our system. For example, each instance was labeled with the service it was hosting as well as storage buckets, database instances, and tables. We also added operational monitoring of labels to track latency and uptime. In essence, we created a “SKU,” to use the retail terminology, for each of our system components to augment the cloud provider SKUs we were already getting. The labeling made it easy for us to map service usage to service costs as well as efficiencies and uptime, and to link DevOps and operational monitoring to financial and cost modeling.
Up until this point, any financial optimization process was built around either partially accurate data or simple metrics such as non-autoscaled cores, memory, and disk capacity. Now, with the rich labeling, BigQuery, and integration of all cloud provider data that was frequently updated, we could finally ask and answer questions about tradeoffs between performance and cost. We could test hypotheses about two or three different ways of attacking a problem. As our growth was accelerating and our risk exposure to cloud infrastructure costs rising, this capability gave us much better visibility into the implications of the product and deployment choices we were making.
Exploring Our Cloud Spending and Product Choices With A FinOps Lens
In the early months of 2019, we looked at our networking costs using our new FinOps microscope (aka BigQuery) and found a real surprise. We had recently added a service (let’s call it “the syncr”) to sync-up some computational results across our various points of presence (PoPs). At the time, we were considering adding more PoPs, and wanted to understand the potential costs.
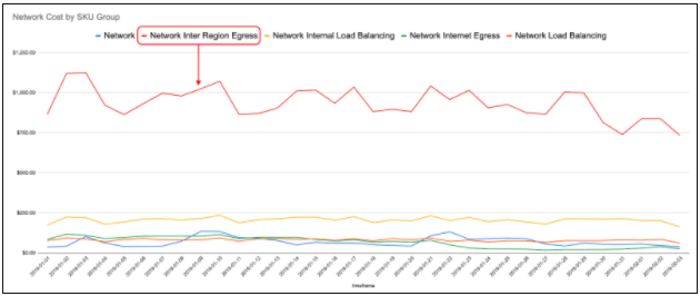
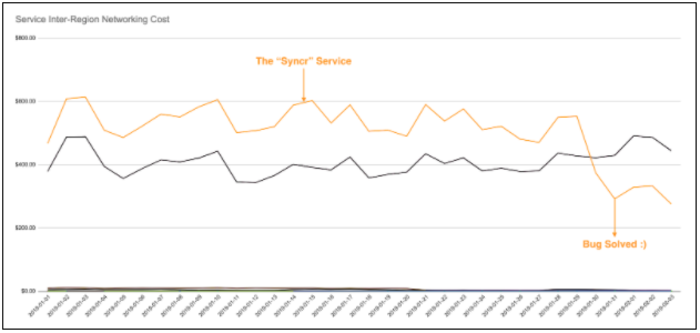
As we were drilling down into this line item, we saw that the majority of our networking costs were due to cross-region networking and that those were coming from the “syncr” services. (you can see the details in images 1 and 2 below). This discovery sparked a review in the team that created the “syncr”; the team quickly discovered a bug causing each sync message to be sent twice. Because the system was written to be idempotent, there was no applicative impact. This is why the bug went undetected until we reviewed networking costs as a FinOps exploration.
[Image 1 – Network Costs by Type]
[Image 2 – Inter-Region Networking Costs By Service Before And After Bug Fix Deployment]
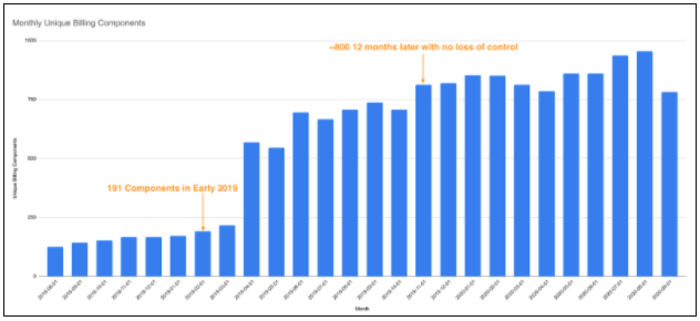
By this point in early 2019, we had deployed and were managing 191 systems! There were daily changes to code, functionality, and configuration of those services. Each change could impact costs. At that point, we knew we needed to teach more people how to manage their cost models (with a FinOps mindset) to make sure those changes took into account the cost impact of the change deployment. With our plans to add more features and products to our product suite, we knew this was paramount if we were to stay on top of our cost models.
[Image 3 – Monthly Unique Billing Components 2018-2020]
We reviewed with each team the composition of our cloud costs (e.g., cores, memory, networking) to make sure everyone was aware of the basics. Then we had specific sessions on measuring the various tradeoffs with things such as preemptible hosts (GCP’s equivalent of spot instances in AWS) versus more expensive instance types as well as some other cloud cost gotchas. These sessions created FinOps advocates and awareness in the various teams. In turn, these advocates and the general awareness of how to practice FinOps, as well as the tools we had put in place, led to teams saving money in cloud costs or thinking more thoroughly about how to optimize for their end goals and priorities (performance vs. cost, etc.).
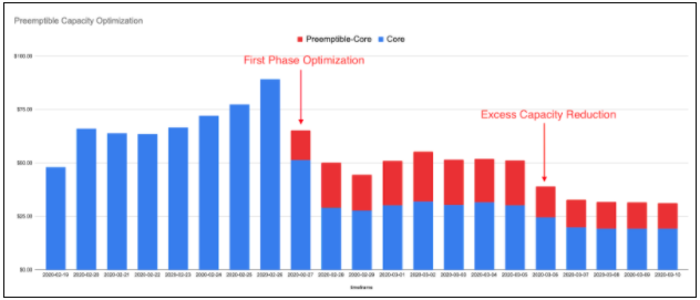
An excellent example of how our FinOps sessions paid off arrived in February of 2020 when one of our teams deployed a new service using regular GCP VMs. Following another round of our FinOps education sessions, team members suggested that this particular service could switch to using the less expensive preemptible hosts with no effect on the service’s SLA. This change brought down the cost of the service by nearly 50%. Those savings went directly to gross margins, with no impact on customer experience or product capability.
[Image 4 – Preemptible Capacity Optimization]
In early 2020 we had already identified most of the low-hanging fruit for optimization in our various systems, leading to diminishing returns on our component-based optimization efforts. The increased challenge in finding ways to make services more efficient was a great indication that it was time to add even more dimensions to our FinOps tooling, which we knew no cloud provider could supply.
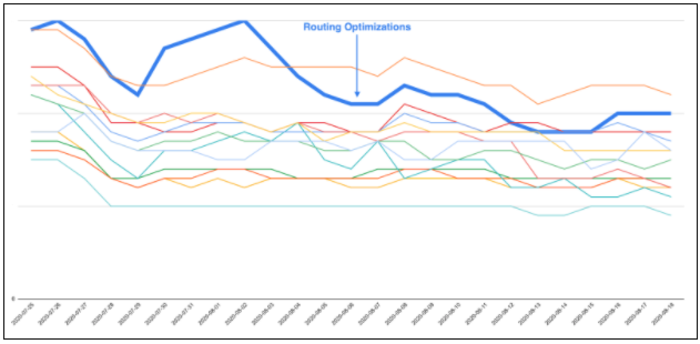
As a multi-tenant SaaS company, we wanted to understand how each customer was impacting our cost model and whether we could optimize at the customer level. This new challenge generated a second wave of optimization ideas, thanks to our internal FinOps advocates and the research from our FinOps team members. We have already implemented one example which involved routing optimizations for certain types of customers and APIs. These optimizations were never flagged as a broad systemic issue. When we viewed this at the account level, it became obvious that routing for some specific API calls could be better cost-optimized without affecting our SLA and response times for those particular customer deployments.
[Image 5 – Routing Optimizations In Early August Bringing In Outlier Account Efficiency Back To Normal]
How to Create a FinOps Mindset In Your Org
FinOps does require some culture engineering to drive adoption. You can be the lone FinOps expert but that works only up to a certain point. To make it more transformational, you need to find other people interested in FinOps on both the Dev and DevOps teams, and you need to make it easy for them to learn it.
Finding FinOps Ambassadors and Pioneers
As any entrepreneur knows, the team is the most crucial factor in the success of any endeavor. If you want to make sure you maximize the probability of success for your FinOps team, they must have the following qualities:
- Care and be curious about how things work
- Care about financial accountability and understand its importance
- Care about the success of the company (obviously)
- Know how your FinOps system works
- Know how cloud architecture and cost structures function and behave
- Know how to make balanced decisions weighing cost, stability, performance, and other tradeoffs
- Can effectively evangelize for a FinOps mindset and rally people on their team and other teams to the cause
As you grow and your FinOps practice matures, if you are doing FinOps right, you will see your team of FinOps ambassadors grow, either organically or out of interest from the surrounding teams. Much like DevOps, FinOps is here to democratize financial accountability rather than create new fiefdoms. That is the only way to effectively and permanently scale the practice.
Making FinOps Visible Makes It More Effective
After we created basic dashboards for key FinOps metrics, we began publishing those dashboards internally and sharing them in DevOps and Dev meetings to communicate what we were doing. Just publishing is not enough. We knew we needed to:
- Make our FinOps methodology, tooling, and user experience obviously useful – as in, good enough to be an internal MVP
- Make it actionable – and highlight ways that our teams could take away information we show them to improve our cost structure, design, or application performance
- Make it meaningful – by clearly demonstrating cost savings over time, conducting debriefs, and including FinOps considerations in the general run of business for our teams
- Create targets – just like any other KPI. We created FinOps KPIs and targets because what is measured and targeted is what people care about
We are now three years into our FinOps journey, and we are still finding opportunities every month to save money or make better operational decisions. Even more important, applying a FinOps lens has become a crucial part of the infrastructure and application design process. Rather than just look to build functionality and retro-fit FinOps, by considering FinOps in advance, we make smarter long-term business decisions that, not coincidentally, also improve the experience of our customers.
We’d love to hear what FinOps challenges you are facing today!