
As a real-time product, HUMAN has strict SLAs in terms of response time and availability. Our scale makes this challenging. We have dozens of zones in nine different regions around the world, hundreds of thousands of payloads processed per second and more than 200 services deployed every day. In our previous blogs, we discussed how we monitor all of these services and ensure we are meeting SLAs.
Today, we want to focus on another field in the world of monitoring: alerts. Alerts have been known to wake you up at night just as you have reached the ultimate sleep cycle. Over the years, we have learned how to manage alerts rather than being managed by alerts. In addition to system stability, employee satisfaction and productivity are directly linked to how many alerts they get during their shift. We want our employees to sleep well at night. Here are a few tips to achieve it.
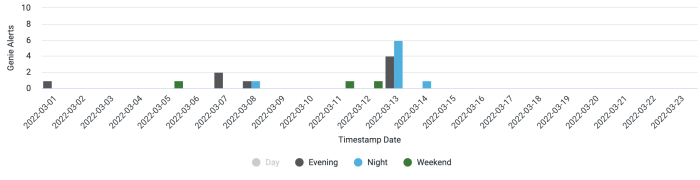
Measure your alerts
Visibility of alerts is the most important thing when it comes to alerts. Each R&D group has its own dashboard showing the number of alerts triggered for the working hours (8:00am-6:00pm), evening hours (6:00pm-12:00am), night hours (12:00am-8:00am) and weekend hours. This dashboard also shows which service triggered these alerts. Our goal is to bring the alerts in all of these levels to zero.
We treat each timeblock differently. For example, alerts during working hours are most often a result of production changes or deployments. On the other hand, alerts during night hours are mostly not a result of deployment changes. Also, If an alert is triggered overnight, it means someone was awakened to deal with the alert, which may impact their productivity the day after.
We review alert data at two points:
Most of the on-call and alert management tools have the data that you can pull and use for your needs. If you want visibility for other tools that aren’t necessarily your on-call tool, you can use products like alertmanager2es.
Alerts only when necessary
This may sound trivial, but it’s very important. Our natural tendency is to be alerted when something is not working. However, something that does not work is not necessarily a violation of the SLA. Asynchronous pipelines are a classic example. There, you can afford some data lag when things are temporarily not working and self-recover.
Superfluous alerts can fatigue team members and cause them to ignore the alerts. Then, when a real alert arrives, it might not be handled properly. We recommend defining the SLA for each service and creating alerts against this SLA only. The remaining cases can be handled by low to medium level alerts that are sent to your monitoring service and are observed offline by a defined routine.
Tune your alerts for maintenance period
Maintenance and alerts do not get along. During a maintenance period, you will likely get a batch of false alarms as a result of production changes. You then ACK ALL to prevent your phone from collapsing. The riskiest thing in this act is that you will miss real alerts.
Because of this, we automatically tune our alerts before a known maintenance period. Alerts that may be triggered due to changes in production are silenced, so we can focus on alerts that are more likely to indicate a real issue. This step should be in every maintenance code you write as pre and post steps.
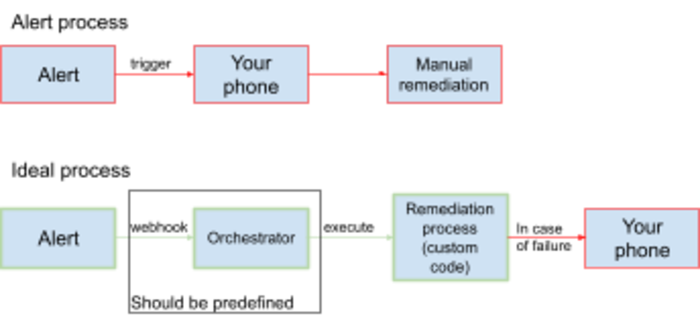
Remediate your alerts automatically
For every alert you receive on your phone, it might make sense to automate it in order to prevent it from occurring again. Most of the time, a simple code can fix things when they are broken. For that, we created an intent in our alert’s handle, Alertmanager, that triggers a simple webhook to our orchestrator. Then, it is simple and easy to integrate remediation code directly to the alerts.
Define your escalation path
Clarifying the path of an escalation is crucial. This path should be documented and the on-call should be aware of it. At HUMAN, we have between two to three tiers of escalations, defined by the level of knowledge and authority that it has to make cross-group decisions.
In case of an issue that involved many teams, we set up a bridge. A bridge should take place verbally on a conference call or in a meeting room, and all stakeholders should be informed on its existence. Make sure that only one person is managing the bridge event. In order to make it easy to trigger this bridge, we have a dedicated group in our on-call management tool.
Conclusion
In summary, writing alerts is the easy part. The hard part is making them effective and avoiding frustrating team members. The concepts mentioned above can help you reduce alert noise and false alarms. They are quite easy to implement, and they send a clear message: we care about your sleep.