
The proliferation of AI crawlers and scrapers presents a new challenge for website owners and security teams. These bots, which gather data for Large Language Models (LLMs) and Retrieval Augmented Generation (RAG) systems, are a growing and often welcome category of traffic, but they also offer attackers a new method to stealthily access site content.
Standard practice dictates that these crawlers and scrapers identify themselves via their user agent strings, and many websites rely on this identifier to manage their traffic.
But as we know, a user agent is not a reliable identifier: it can easily be spoofed. This raises a critical question: how much of the traffic that claims to be from a legitimate AI crawler is authentic?
To answer this, we conducted a two-week analysis of traffic associated with 16 well-known AI crawlers and scrapers. Our research revealed that unauthorized scrapers and other malicious actors regularly use AI crawler user agents to disguise their activity and bypass anti-bot measures.
In this Satori Threat Intelligence research blog, we’ll break down the tactics used in these spoofing campaigns and identify which AI crawlers are the most frequent targets of impersonation. Key findings from our analysis include:
HUMAN Sightline successfully blocked 99.89% of spoofed traffic, preventing it from reaching customer applications.
Understanding the Impersonation Target: LLM vs RAG Crawlers
The terms AI scrapers and AI crawlers can be misleading. Despite what their names suggest, these tools are not powered by AI; their methods are similar to those of conventional web scrapers and crawlers, but they’re built to extract content for AI systems and models.
AI companies typically operate two main types of scrapers and crawlers, each with a distinct purpose:
This distinction is important because, as our data shows, attackers have a clear preference for impersonating one type over the other. AI scrapers and crawlers, like other commercial bots, are expected to identify themselves so that websites can manage bot traffic. However, attackers can abuse this norm by attempting to impersonate legitimate AI-focused bots, such as through co-opting the legitimate tool’s user agent. In this report, we’ll discuss why flagging these tools based solely on easily-spoofable attributes like user agent is not enough.
Research Methodology
This research analyzed a two-week period of traffic associated with well-known AI scrapers and crawlers, using the user agent strings and network information from their official documentation. The dataset spanned multiple industries and geographies across HUMAN customers.
The goal was to distinguish between two types of traffic:
To quantify our results, we use the “Spoof Ratio”—a metric representing the number of verified requests for every one spoofed request. A high spoof ratio indicates that most of a crawler’s traffic is legitimate, while a low spoof ratio points to significant impersonation and exploitation of that crawler’s identity.
The Scale of AI Crawler Spoofing
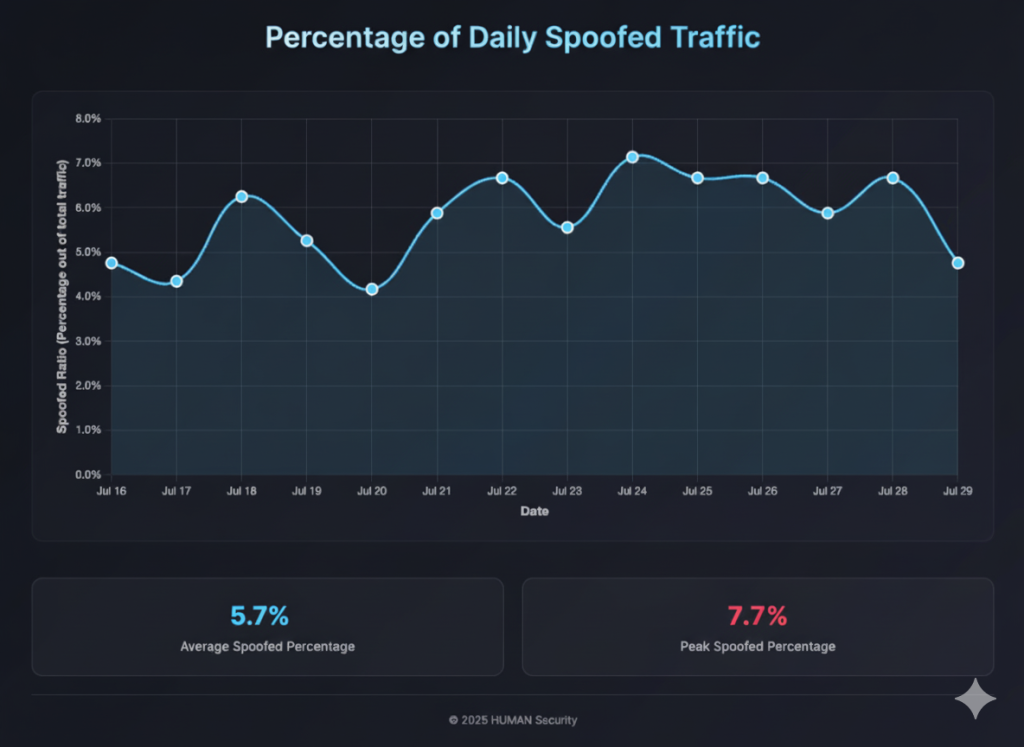
Our analysis reveals that AI crawler spoofing is a significant and widespread issue. Across all observed traffic, the average spoof ratio is 1:17, meaning that 1 in every 18 requests using an AI crawler user agent is a fake! In total, spoofed requests make up 5.7% of all traffic labeled as coming from AI crawlers.
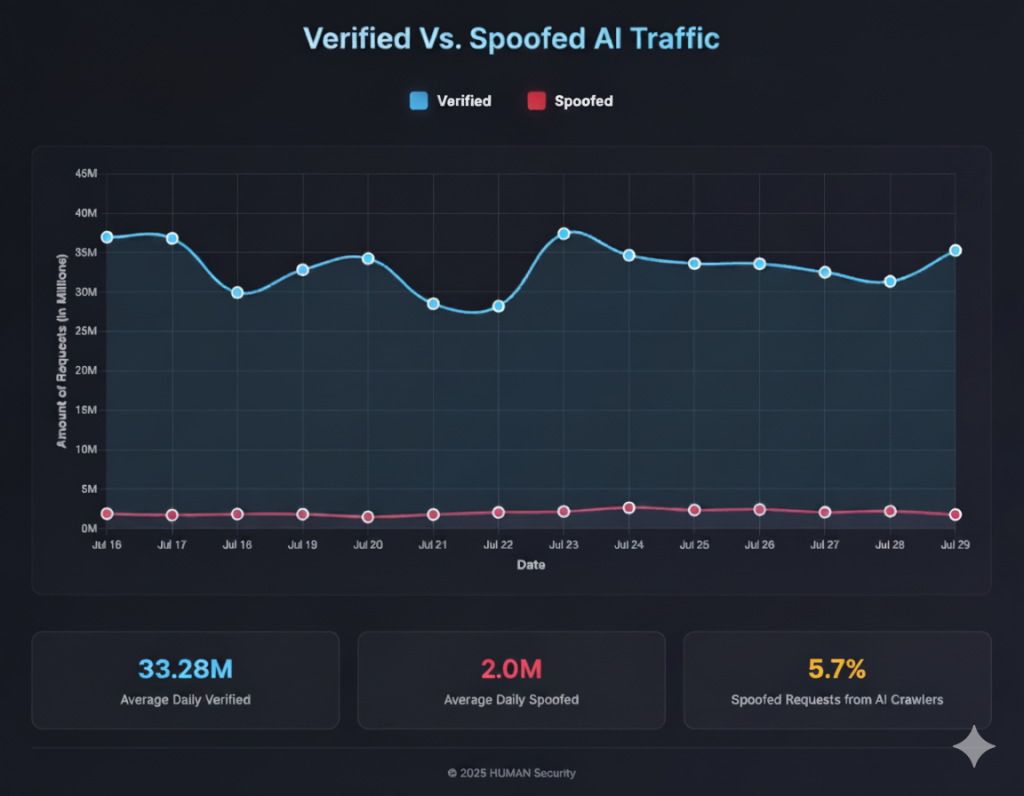
On a daily level, the average spoof ratio is 1:16.8 (Figure 1), equivalent to over 2M spoofed requests per day (Figure 2).
High-Volume Spoofed Scraping Targets Content-Rich Platforms
Attackers targeted a wide range of industries, but showed a clear preference for content-rich platforms, especially those in education, online news, and photo-sharing communities. Other heavily targeted sectors include marketing platforms, real estate, travel sites, and online retailers. This pressure is not limited to high-profile brands; organizations of all sizes saw spoof attempts.
The primary attack vector of the spoofed traffic is persistent, high-volume scraping.
In one case, a luxury real estate listing in a major US metro was scraped over 54,000 times on one site. The same property was also scraped across 19 different platforms, resulting in a total of 88,900 scraping attacks. Across the same city, more than 343,000 spoofed requests targeted over 25,000 listings. This pattern and volume of scraping attacks suggests competitive monitoring efforts, possibly driven by rival real estate agencies in that market.
We also observed business intelligence scraping at scale. The next three most targeted assets were three separate earnings reports from a single corporation, each scraped between 31,000 and 43,000 times. Additional high-frequency targets included car listings, online academic books, and even an article about oversized avocados, each drawing over 15,000 spoofed scraping attempts.
Your Guide to Safely Adopting Agentic Commerce
See how AI agents are changing discovery and purchase, explore the emerging trust frameworks, and learn what readiness looks like for the agent-driven economy.

RAG Crawlers were Impersonated the Most
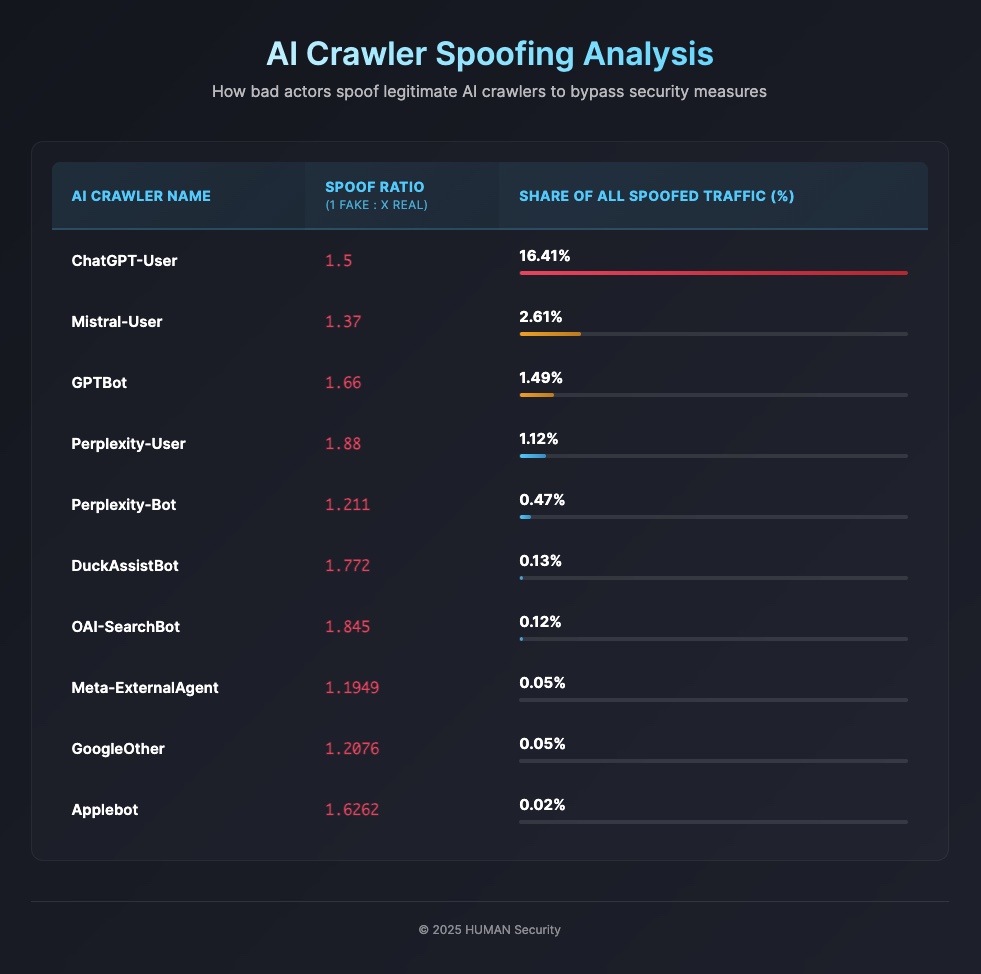
The most frequently exploited AI crawlers’ user agents are those used for Retrieval-Augmented Generation (RAG). Among them, OpenAI’s ChatGPT-User shows the highest spoof ratio at 1:5, followed by MistralAI-User at 1:37, and Perplexity-User at 1:88.
This high level of exploitation aligns with OpenAI’s overall spoof ratio of 1:9, the highest among all major brands. By comparison, MistralAI follows at 1:37, Perplexity at 1:138, and DuckDuckGo trails with a very distant 1:772.
We can’t say for sure why attackers prefer to impersonate these crawlers. Still, we can hypothesize that it is because RAG crawlers are both highly trusted and operationally convenient as a disguise. Site operators often allow them for perceived benefit (such as providing visibility or traffic), which means fewer blocks or challenges compared to other bots. Their on-demand, interaction-driven traffic patterns also blend easily with legitimate requests.
Note: These findings concern spoofing of AI crawler user agents. This is distinct from OpenAI’s ChatGPT Agents, which HUMAN verifies cryptographically. Because those requests are signed and validated against OpenAI’s keys, they cannot be spoofed in the same way as crawler traffic. OpenAI documentation explains how this works.
Let’s take a closer look at the specific spoofing campaigns behind these high spoof ratios and explore how spoofed traffic targets each of these three crawlers.
The Anatomy of a High-End Scraping Operation
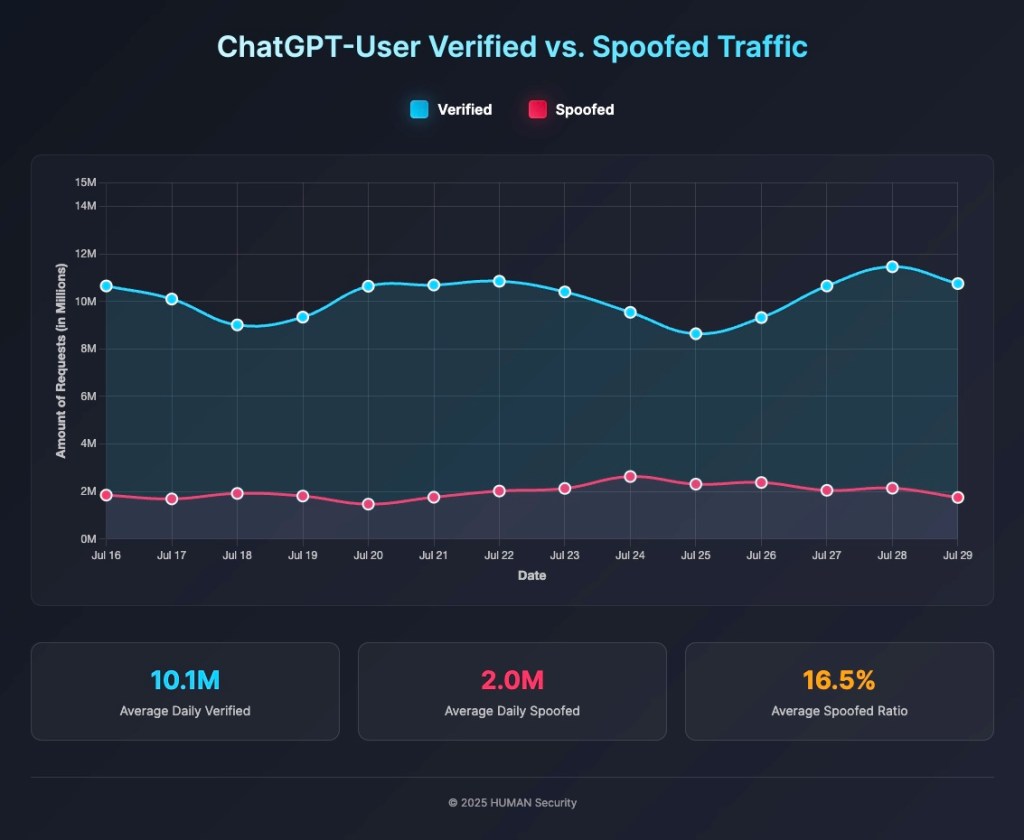
As noted above, OpenAI’s ChatGPT-User crawler stands out as the most heavily spoofed, with a striking spoof ratio of 1:5, meaning one in every six requests is spoofed.
Interestingly, the volume of spoofed ChatGPT-User traffic was consistent at approximately 1.99 million requests per day, while verified traffic tended to fluctuate with actual usage. This stability suggests the presence of persistent, well-established spoofing campaigns targeting these crawlers.
Upon further investigation, we found that the spoofed ChatGPT-User traffic is a prime example of what we call a high-end spoofing campaign.
Unlike basic spoofing that only fakes a user agent, these campaigns carefully mimic the network characteristics of legitimate traffic. This strategy exploits the fact that while some security teams may verify a user agent and its network’s ASN, they often don’t check if each IP address aligns with the official documentation.
Abusing the ASN
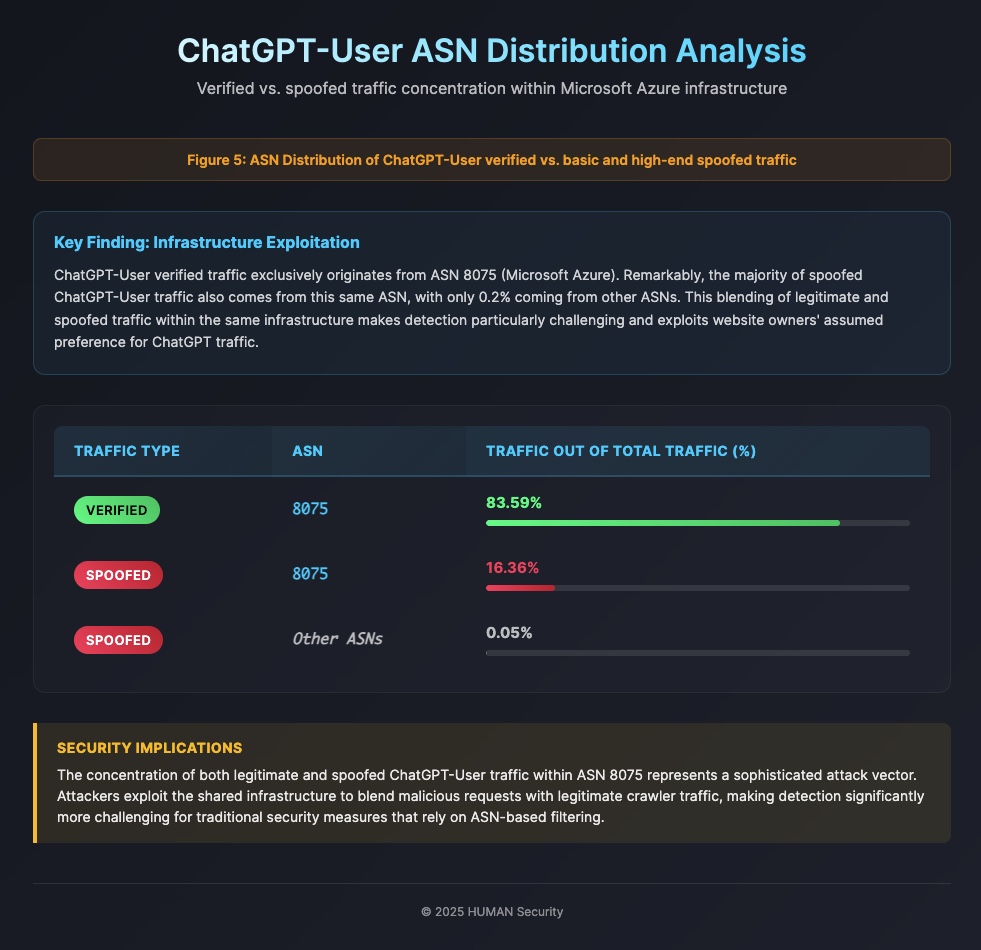
Take ChatGPT-User’s verified traffic as an example: it exclusively originates from ASN 8075, a Microsoft Azure ASN that serves a broad range of customers beyond just OpenAI’s crawling operations. Remarkably, the majority of spoofed ChatGPT-User traffic also comes from this same ASN. Only a small fraction, about 0.2%, are basic spoofing campaigns coming from other ASNs. This blending of legitimate and spoofed traffic within the same ASN not only makes detection particularly challenging but is also designed to exploit website owners’ assumed preference for ChatGPT traffic and their often limited security measures.
IP Proximity Deception
Zooming in even further reveals that this high-end spoofing campaign doesn’t just rely on sharing the same ASN—it also employs a tactic we call IP Proximity. Instead of strictly verifying each IP address against official ranges, attackers focus on appearing within nearby subnets or IP blocks that look similar but aren’t authorized. This subtle difference is often overlooked, as many defenders only verify traffic against the main subnets and not the full range of addresses.
For example, OpenAI’s ChatGPT-User official documentation lists IP ranges such as 40.84.221.224/28 and 40.84.221.208/28. However, we observe over 14,000 requests coming from the IP address 40.84.221.0, which lies close to but is not included within those CIDRs. Similarly, IP addresses 74.7.35.0 and 74.7.36.0 generated 14,000 and 21,000 spoofed requests, respectively. These IPs fall near the official CIDRs:
This tactic exploits the assumption that IPs close to official ranges are legitimate, making it easier for spoofed traffic to slip through standard checks.
Orchestrated Attacks with Serverless Functions
The same high-end spoofing techniques were observed in campaigns targeting other RAG crawlers, including MistralAI-User (1:37 ratio) and Perplexity-User (1:88 ratio). Beyond IP proximity, these campaigns leverage another sophisticated method: orchestrated scraping attacks using serverless functions.
These edge serverless functions, which we will refer to as “Workers,” are lightweight programs that run in a serverless environment without requiring traditional server setup. This makes them efficient, scalable, and particularly attractive for attackers running distributed scraping campaigns. Workers can be configured to send HTTP requests with custom headers and logic, essentially acting as remote-controlled bots executing a predefined configuration and with a high level of anonymity. Once deployed, the worker handles the full orchestration of the attack across various ASNs, CIDRs, and IPs.
Case Study: The AI Blog Attack
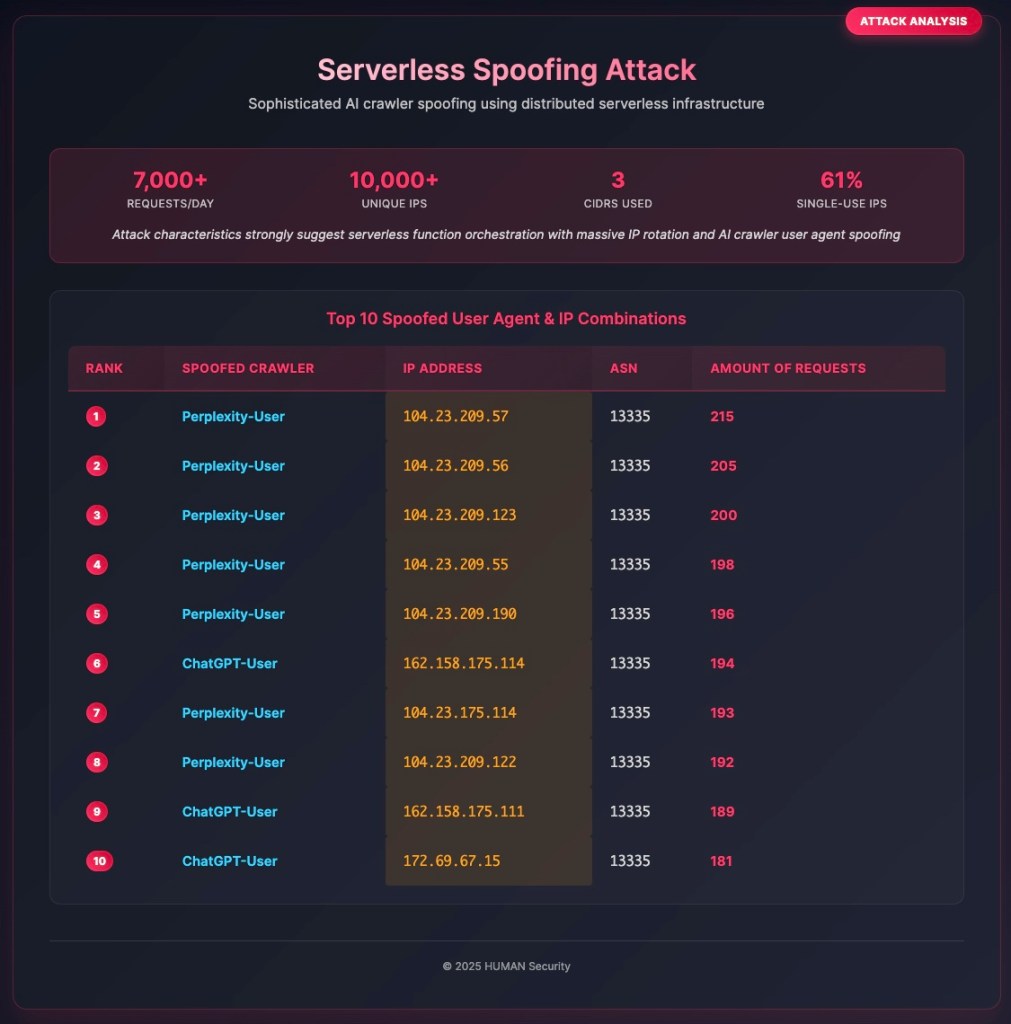
We uncovered a high-end spoofing attack whose characteristics strongly suggest it was orchestrated using a serverless function, in this case, a worker on a major CDN, that targeted a customer’s AI-focused blog. This persistent attack generated over 7,000 requests per day, all originating from a single CDN-operated ASN and rotating across just three distinct CIDRs. Each request spoofed a known AI crawler user agent, mainly Perplexity-User, MistralAI, or ChatGPT-User.
More than 10,000 different IPs were used throughout the attack, with each IP sending an average of only 10 requests, and 61% of those IPs sending just 1–2 requests in total. This combination of massive IP rotation, frequent user agent spoofing, and low request volume per IP raises strong suspicion of serverless function usage, since they allow attackers to quickly run short tasks across thousands of different IPs, then shut them down just as fast.
Key Takeaways for Defenders
AI crawler spoofing is active and widespread. User agents can’t be trusted on their own, and attackers know RAG crawlers are often given a pass. Effective defense means checking every request against the crawler’s published ASN and IP ranges, not just the user agent string.
Allowlists need to stay current. If you don’t update them regularly, you’ll miss when vendors shift their infrastructure. High-end campaigns make detection harder by using IPs just outside official ranges or spraying low-volume traffic across thousands of serverless “Worker” IPs.
The lesson is straightforward: exact network-level verification is the baseline if you choose to allow crawler traffic. Without it, attackers will keep using AI crawler user agents as cover to scrape and probe your site.
Control AI Scrapers and Crawlers with HUMAN Sightline
HUMAN Sightline Cyberfraud Defense gives you visibility and control over bots, crawlers, and LLM scrapers. In the console, you can block, allow, or send scraping traffic to a paywall, and track the paths these agents take through your site. For bots you choose to allow, our integration with TollBit lets you meter and monetize access on a per-use basis. For everything else, we enforce policies at the edge so unwanted scrapers are stopped before they touch your content. If you want an assessment of your current policy, talk to our team.
Get visibility and control over AI agents and agentic browsers on your website.
