
Last updated: January 2026.
The internet is full of bots. They generate almost as much traffic as people do.
But while many of them are malicious scrapers or spammy impostors, let’s not forget about the many “good” bots that serve legitimate functions, like indexing your content for Google search or generating preview cards when your link gets shared on X. In 2026, that “good automation” umbrella increasingly includes AI agents and agentic browsers that research, compare, and take actions on behalf of real users.
These are the helpful worker bees of the internet. If you accidentally shut them out in your haste to seal off malicious bots, you’ll create some serious headaches for yourself: buried search results, broken preview links, disrupted integrations, and so on.
Of course, even these legitimate bots (also called known bots) can hog your bandwidth and skew your analytics. And the volume profile is changing quickly: HUMAN telemetry shows agentic traffic is accelerating sharply, up 6900% YoY. So the key is to strike the correct balance, being intentional about which bots you welcome and which you exclude. To this end, there are specific ways to modify the way some of these crawlers interact with your site, which we’ve described below where applicable.
In this guide, we’ll use our analytics, gained by verifying more than 20 trillion digital interactions each week, to take a deep dive into the world of legitimate bots, going well beyond the usual suspects like Googlebot and Bingbot. You’ll find a detailed list of known crawlers, complete with their user agent strings, and learn how to spot some of the most common types, figure out who sent them, and determine what, exactly, they want from you and your domain.
Your Guide to Safely Adopting Agentic Commerce
See how AI agents are changing discovery and purchase, explore the emerging trust frameworks, and learn what readiness looks like for the agent-driven economy.

Basic Bot Identification: User Agents and Patterns
When a legitimate bot visits your site, it identifies itself with a user agent string: A snippet of text that usually contains the name of the bot or of the company that owns it (e.g., Googlebot or Bingbot).
Because known bots follow these predictable naming conventions, they can be detected using regex patterns. For example, Googlebot’s UA string includes the word “Googlebot,” and Facebook’s crawler uses “facebookexternalhit” or “Facebot.”
A quick note on security: Because malicious bots can fake the UA strings of legitimate ones, you need a decent bot detection system to sort the good players out from the bad ones. This is increasingly true for AI crawlers: in a recent HUMAN analysis of traffic associated with 16 well-known AI crawlers and scrapers, 5.7% of requests presenting an AI crawler/scraper user agent were spoofed.
Which Bots Visit Your Site the Most?
Knowing how often certain bots are crawling your site is one of the major factors in deciding which ones to allow and which ones to throttle.
As you can tell from the chart below (drawn from our observations over a 30-day period), legitimate bot traffic is dominated by Google’s main web crawler, followed by Bing’s. Together, they account for more than 60% of all requests from known good bots. Some other notably active crawlers are the ones operated by Facebook and Pinterest.
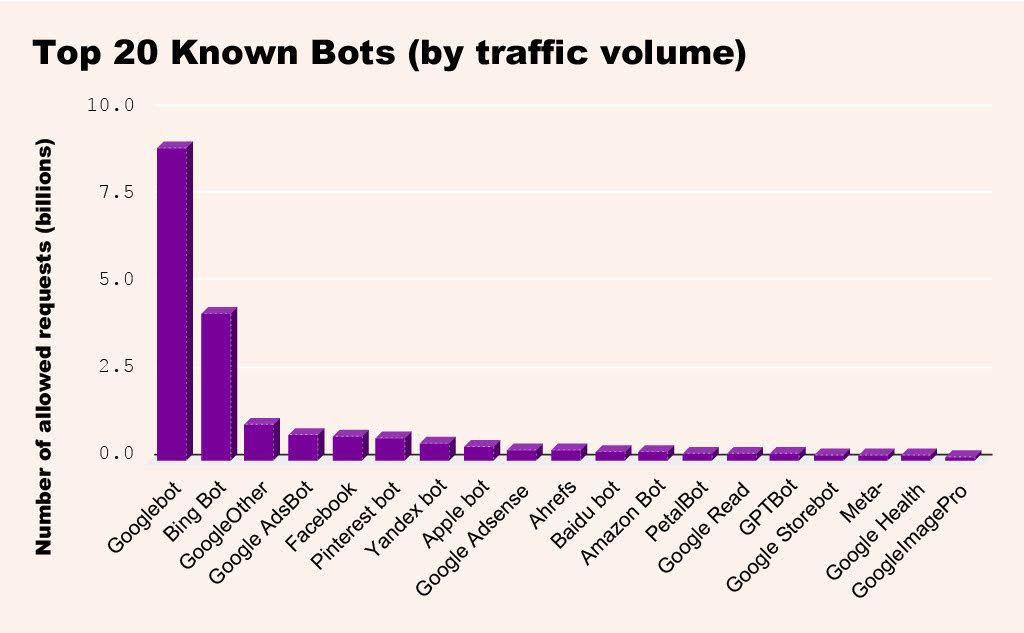
Incidentally, OpenAI’s crawler, GPTBot, was number 16 on our list, generating almost a full percent of all legit-bot traffic. That’s a pretty significant amount of activity for this relative newcomer.
Now that we understand which “good” bots are visiting your network and how often, it’s time to learn why they’re on there in the first place.
Let’s go over the major categories of legitimate bots and learn how to identify some of the major players in each field:
Search Engine Crawlers
Think of a search engine crawler (like the aforementioned Googlebot) as a digital explorer that roams the uncharted web, hunting for content to bring home and display on its engine’s results page.
While these crawlers are critical for your domain’s SEO visibility, they can get a little greedy with server resources, so use robots.txt to guide them to only the most relevant areas of your site.
Googlebot
Googlebot is Google’s main web crawler that indexes pages to display in Google search results. You should never block it, unless you’re trying to turn your page into an un-googleable ghost site. If you do want to manage Googlebot, you can throttle its crawl rate on Google Search Console.
Google also runs some specialized crawlers for news, images, and so on, but they always have “google” or “googlebot” in their UA strings.
User agent: Googlebot
Sample UA string: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Bingbot
Bingbot is Microsoft’s search crawler that indexes pages for Bing. As the chart above shows, it’s second only to Googlebot in traffic volume. It’s also essential for Bing SEO, so we recommend not blocking this one either.
Bing runs some specialized bots like MSNBot and BingPreview, but they always contain “bing” in the UA string. Crawl management is available via Bing Webmaster Tools.
User agent: bingbot
Sample UA string: Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
Yahoo! Slurp
Slurp is Yahoo’s legacy crawler that indexes content for Yahoo! Search. This living relic of the early 2000s web isn’t spotted a lot these days, but it’s still out there; if you’re lucky enough, it may pay you a visit (especially if you’re outside the US).
User agent: Slurp
Sample UA string: Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
Baidu Spider
Baidu Spider is the bot behind China’s biggest search engine, Baidu. It’s essential for visibility in Chinese-language markets, but you might encounter it globally as well.
This crawler doesn’t have an opt-out mechanism, and it may inconsistently obey directives from robots.txt.
User agent: Baiduspider
Sample UA string: Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Yandex Bot
Yandex Bot is the web crawler for Yandex, Russia’s most popular search engine. It’s especially important for websites targeting Russian or Eastern European visitors. Its crawl settings can be modified using the Yandex Webmaster toolkit.
User agent: YandexBot
Sample UA string: Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
SEO and Marketing Analytics Crawlers
Another common type of crawler is used to gather data for marketing analytics: performing SEO audits, checking backlinks, researching competitors, and so on.
These bots can offer useful marketing insights, but they can also be a little inconsiderate with their volume of requests. Sometimes they need to be kept on a short leash or blocked entirely. (Like a lot of the bots on this list, they frequently have built-in opt-out mechanisms.)
AhrefsBot
AhrefsBot is the crawler behind the popular Ahrefs SEO tool. It scans sites for backlinks and other metrics. Our data shows that this bot is in the top ten most active “good” bots (see the above chart), so you’re pretty likely to see it in your logs.
To stop AhrefsBot from crawling your site, you can opt out by emailing [email protected].
User agent: AhrefsBot
Sample UA string: Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)
SemrushBot
SemrushBot is the crawler behind Semrush’s SEO toolkit. It serves a similar purpose to AhrefsBot, scanning sites for keyword rankings, backlinks, and competitive data. It’s a useful tool for digital marketers, but might need to be throttled if it visits too frequently.
User agent: SemrushBot
Sample UA string: Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
Majestic MJ12Bot
MJ12Bot is used by Majestic SEO to map the web’s link graph for Majestic’s backlink index. It’s useful for SEO research, but its aggressive crawling might require tuning if your site gets a ton of traffic from it.
Check the MJ12Bot website for information on how to block or throttle it.
User agent: MJ12Bot
Sample UA string: MJ12bot/v1.4.0 (http://www.majestic12.co.uk/bot.php?+)
Social Media and Content Preview Bots
This type of crawler is mainly used by social media platforms to create content previews for links that are shared. Blocking them can mess with the appearance of links to your content, so in general it’s best to allow them.
If your site has pages you want to keep confidential, make sure to use the correct meta tags or authentication, because these preview bots will fetch anything that’s public.
Facebook Crawler
Facebook’s crawler scans shared links to generate previews for posts and messages. It’s a major bot (ranking in the top 5 of our traffic volume data), and allowing it is crucial if you want your content to show up correctly when it gets linked from Facebook or Instagram. Make sure it can access your site’s OG tags.
User agent: facebookexternalhit (most commonly)
Sample UA string: facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
Twitterbot
Twitterbot is X’s crawler that scans shared links to generate preview cards. If you block it, posts linking to your site won’t show a preview, just a bare URL.
User agent: Twitterbot
Sample UA string: Twitterbot/1.0 Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.12.3 Chrome/69.0.3497.128 Safari/537.36
LinkedInBot
Another preview crawler, this time for LinkedIn’s platform. As with Facebook and X’s crawlers, blocking it will result in broken or missing previews on posts that link to your content.
User agent: LinkedInBot
Sample UA string: LinkedInBot/1.0 (compatible; Mozilla/5.0; +http://www.linkedin.com)
Slackbot
Slack’s crawler that creates preview cards for links that are shared in Slack channels. This one could also be considered an integration bot, but we’re listing it here because creating link previews is its main job.
User agent: Slackbot
Sample UA string: Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)
Pinterestbot
Pinterest’s web crawler is extremely active; in fact, it ranked #6 in our traffic stats, just behind Facebook. It saves page content and images when someone pins something.
User agent: Pinterestbot
Sample UA string: Mozilla/5.0 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html)
Monitoring and Uptime Bots
These “guardian angel” bots regularly check a site’s availability and response time to alert its owner of outages.
They’re useful for making sure your site stays online, but they can cause noise in visitor logs if their activity isn’t filtered out. If you use this type of service on your site, make sure to whitelist the bots in your detection system, but exclude them from your visitor stats.
Pingdom
Pingdom is a monitoring service that uses bots to ping a site at regular intervals to check its uptime and performance. These frequent “health check” visits should be filtered from analytics to avoid skewed data.
User agent: Pingdom.com_bot
Sample UA string: Pingdom.com_bot_version_1.1 (+http://www.pingdom.com/)
UptimeRobot
Another common uptime checker. It checks a site every few minutes and will alert the owner if it detects downtime.
User agent: UptimeRobot
Sampe UA string: UptimeRobot/2.0 (+http://www.uptimerobot.com/)
BetterStack Bot
Another uptime checker we spotted in our data. (Formerly called Better Uptime.)
User agent: BetterStackBot
Sample UA string: BetterStackBot/1.0 (+https://betterstack.com/docs/monitoring/uptime-robot/bot/)
cron-job.org
A free service that triggers URL pings and other actions at user-scheduled intervals. This one can also show up in visitor logs.
User agent: cron-job.org
Sample UA string: cron-job.org/1.2 (+https://cron-job.org/en/faq/)
AI and LLM Data Crawlers and RAG Scrapers
These crawlers and scrapers—often operated by AI companies or their ecosystem partners—collect web content so AI systems can (1) build and improve models, or (2) retrieve fresh context on demand to answer a user’s question. Importantly, most of this “AI bot” traffic is not inherently intelligent: the automation typically looks like classic crawling and scraping.
To manage them effectively, it helps to separate two common subtypes:
This is a relatively new and fast-growing segment of automation. It has also become easy to talk about imprecisely—teams will often lump “AI crawlers,” “scrapers,” and “agents” together, even though they behave differently and call for different controls. You can learn more about the distinct types of bots in the AI ecosystem and their purposes here.
For a deeper look at practical controls—blocking uninvited bots, allowing trusted crawlers, and even monetizing AI requests—see our posts on AI-driven content scraping and on the HUMAN + TollBit integration, which allows monetization of LLM Crawlers on a pay-per-crawl basis.
OpenAI’s GPTBot
GPTBot is the main web crawler used by OpenAI to gather training data for ChatGPT and its other AI models. It can be blocked using robots.txt, or by denying access to its IP range.
See OpenAI’s crawler documentation for more detailed information about how to rein in GPTBot, as well as the company’s other bots.
User agent: GPTBot
Sample UA string: GPTBot/1.0 (+https://openai.com/gptbot)
OpenAI’s ChatGPT-User
ChatGPT-User is an agent that simulates end-user browsing on behalf of ChatGPT conversations, fetching live webpages so that ChatGPT can cite fresh information. ChatGPT-User is not used for crawling the web in an automatic fashion, nor to crawl content for generative AI training. Because it impersonates a browser shell, the traffic can be bursty and may inflate analytics. It does not consistently respect robots.txt, so filter on the UA substring “ChatGPT-User” or block at the firewall if needed. You can also access OpenAI’s crawler documentation (linked above) for instructions on managing this bot.
User agent: ChatGPT-User
Sample UA string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
OpenAI’s OAI-SearchBot
OAI-SearchBot is optimized for real-time retrieval and indexing rather than bulk training. Expect short, frequent bursts as it follows links from ChatGPT answers and other OpenAI products. Robots.txt directives are usually ignored, so block via the UA substring “OAI-SearchBot” or by IP.
User agent: OAI-SearchBot
Sample UA string: Mozilla/5.0 (compatible; OAI-SearchBot +https://www.openarchives.org/Register/BrowseSites)
Anthropic’s ClaudeBot
ClaudeBot is Anthropic’s main web crawler. It gathers text used for training the Claude AI assistant. The company’s other crawlers include Claude-User and Claude-SearchBot.
Anthropic’s website contains information about how to limit the crawling activity of their bots. For further support, you can also contact [email protected] using an email address from the domain in question.
User agent: ClaudeBot
Sample UA string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; [email protected])
Anthropic’s anthropic-ai
Anthropic formerly operated a second crawler, distinct from ClaudeBot, that identifies itself simply as anthropic-ai. It appeared to gather publicly available text for training and evaluating Anthropic’s Claude models. The bot did not honor robots.txt.
However, Anthropic told reporters in July 2024 that the anthropic-ai and claude-web agents were deprecated in favor of ClaudeBot. If you still see traffic with the string above, it is almost certainly legacy or spoofed traffic.
User agent: anthropic-ai
Sample UA String: Mozilla/5.0 (compatible; anthropic-ai/1.0; +http://www.anthropic.com/bot.html)
PerplexityBot
Run by Perplexity AI, this crawler gathers page content used to generate cited answers in Perplexity’s “answer engine.” Like most LLM scrapers it disregards robots.txt. To exclude it, deny requests bearing the UA “PerplexityBot” or use Perplexity’s published opt-out header.
User agent: PerplexityBot
Sample UA string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://docs.perplexity.ai/docs/perplexity-bot)
AI Agents and Agentic Browsers
AI agents and agentic browsers represent a new class of automation on the web: user-directed sessions where an AI system browses, clicks, and completes multi-step tasks on a person’s behalf. In practice, this shifts browsing from navigation to delegation—traffic originates from genuine user intent, but executes at the pace and precision of automation.
For site owners, the operational reality is that agentic sessions often look like ordinary human browsing at the protocol level (Chromium/Edge-like clients, standard TLS and headers), while behaving differently: compressed multi-step workflows, more systematic navigation, and higher action density. That makes traditional controls—UA filtering, IP heuristics, and robots.txt—insufficient for reliably identifying or governing this traffic.
The stakes are rising quickly. HUMAN telemetry shows verified AI agent traffic grew more than 6,900% YoY in 2025, and the competitive mix is diversifying as new agentic browsers and extensions enter the market. At the same time, agentic interactions skew heavily commercial, over 85% are product-related, with conversions from agent-recommended results materially higher than traditional search.
Most AI A
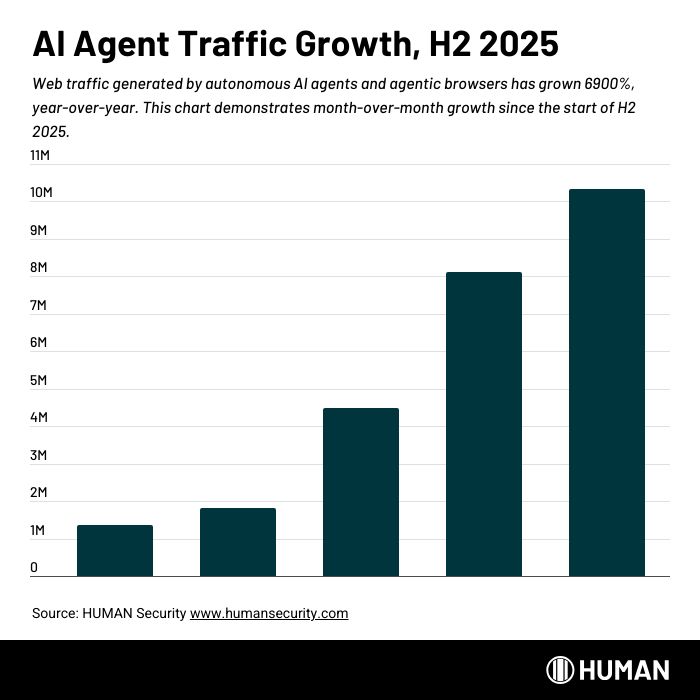
Note: Many agentic browsers intentionally resemble standard Chromium at the fingerprinting level, so user-agent checks often won’t reliably differentiate agent-driven sessions from normal Chrome traffic. For detection and governance, we recommend using behavioral and client-side signals (for example, automation framework artifacts, extension/instrumentation fingerprints, and interaction patterns) and enforcing policies based on intent and impact rather than claimed identity. You can learn more from our recent research.
ChatGPT Agent
ChatGPT Agent is OpenAI’s autonomous agentic system that can plan and execute multi-step tasks inside a virtual browser/computer (navigation, form fills, and workflow completion). Unlike classic crawlers, sessions are user-directed but automation-executed, which can create bursty, high-density browsing patterns that resemble “fast humans” in analytics.
From a governance perspective, ChatGPT Agent is notable because it can self-identify cryptographically: requests include HTTP Message Signatures (RFC 9421), including a Signature-Agent value set to “https://chatgpt.com,” enabling verification against OpenAI’s public key directory. This is specifically positioned as a safeguard against AI agent spoofing.
User agent: Variable, generic modern Chrome UA (do not rely on UA for detection).
ChatGPT Atlas
ChatGPT Atlas is a Chromium-based browser that embeds ChatGPT into the browsing experience and adds “agent mode,” enabling the assistant to navigate, click, and fill forms on a user’s behalf. Because it operates as a full browser, Atlas traffic is best understood as user-privileged automation inside a real browsing session (not a crawler).
Critically, Atlas is designed to look like normal Chrome: the default UA is typically identical to Chrome on macOS and includes no “Atlas” token, and there is no public signed identity signal for Atlas browsing traffic. As a result, you should assume UA filters and robots.txt controls will be ineffective for reliably identifying Atlas-driven sessions.
User agent: Standard Chromium UA (often identical to latest Chrome on macOS).
Claude for Chrome
Claude for Chrome is Anthropic’s AI-powered Chrome extension that can summarize pages, draft content, and orchestrate multi-step browsing tasks across tabs. For your site, this typically shows up as real-user browsing intent executed through dense automation inside a local Chrome session—often with more systematic navigation and fewer idle gaps than typical users.
Because it runs as a browser extension, it inherits the user’s browser context and presents as standard Chrome traffic at the network layer. That means robots.txt and UA-based filtering are not dependable controls for separating Claude-driven sessions from normal users.
User agent: Inherits user’s Chrome UA string
Microsoft’s Copilot Actions
Copilot Actions is Microsoft’s agentic automation framework for executing user-directed workflows across apps and services, including browser-based actions (Edge) and cloud-hosted browser execution (copilot.com). It can navigate, click, scroll, and type to complete tasks, compressing complex journeys into short windows.
From a web-traffic standpoint, Copilot Actions may appear as ordinary Edge/Chromium browsing in protocol and TLS, with no simple “bot UA” to target. Detection and governance should focus on session structure (highly consistent multi-step sequences, retries, and dense activity) rather than headers alone.
User agent: Inherits the user’s browser UA.
Google Mariner
Google Mariner is DeepMind’s browser agent that uses Gemini to “see” what’s on a Chrome screen and execute multi-step tasks (forms, shopping flows, bookings, information retrieval). In practice, Mariner sessions can resemble a single highly capable user driving a full Chrome instance, but with AI-planned actions rather than direct human navigation.
Mariner appears when users delegate browsing work through Gemini/Mariner interfaces, often producing dense sequences across discovery → filtering → cart/checkout-like steps (with user confirmation for sensitive actions).
User agent: Inherits the user’s Chrome user agent.
Perplexity Comet
Perplexity Comet is a Chromium-based AI-first browser that embeds Perplexity’s assistant directly into browsing. Users delegate browsing tasks—summarization, cross-tab synthesis, comparisons, form fills, and shopping workflows—so traffic originates from human intent but executes at automation speed and density.
Comet does not provide a per-request verifiable identity signal and can present as ordinary human browsing. The doc’s framing is explicit that user-agent and header claims are weak (identities are routinely spoofed), so reliable handling depends on behavioral context, automation artifacts, and enforcing what the session attempts to do (read/navigate vs state-changing actions).
User agent: Chromium-based UA strings with Perplexity-specific headers; robots.txt compliance is described as limited for user-initiated activity.
Security and Vulnerability Scanners
Security-focused web crawlers scan domains for vulnerabilities like exposed databases or vulnerable plugins (often for threat research purposes).
Reputable scanners like the ones listed here will announce themselves with clear UA strings, and they often provide opt-out options. Malicious scanners, on the other hand, typically disguise their activity and ignore opt-out protocols.
A visit from a legitimate security scanner can be a pretty useful cue to check your network for issues (as in, Why is Shodan scanning me? Is everything secure?). But they’re also capable of generating a fair amount of traffic, so some admins choose to block them via firewall.
Censys.io
Censys.io’s web crawler is a security research bot that scans the internet for exposed devices and other network vulnerabilities. It’s used widely in the cybersecurity industry for threat intelligence and improving network resilience.
See Censys’s documentation for more detailed information about how to opt out of data collection.
User agent: censys.io
Sample UA string: Mozilla/5.0 (compatible; CensysInspect/1.1; +https://about.censys.io/)
Shodan
Shodan’s crawler also indexes connected devices, collecting data on open ports and other vulnerabilities.
User agent: shodan
Sample UA string: Mozilla/5.0 (compatible; Shodan/1.0; +https://www.shodan.io/bot)
BitSight
Companies like BitSight generate security ratings for websites and networks by using bots to scan them for vulnerabilities. Their scans are non-invasive, but their probing can still trigger security alerts.
User agent: BitSightBot
Sample UA string: Mozilla/5.0 (compatible; BitSightBot/1.0)
Best Practices for Managing “Good” Bots
Even bots with legitimate purposes—such as indexing content, generating link previews, or monitoring uptime—can cause issues if not properly managed. They might strain infrastructure, distort analytics, or access content you’d rather keep restricted. Smart bot management involves applying appropriate controls based on the bot’s identity, behavior, and impact.
Here are five best practices for keeping “good” bot traffic truly beneficial.
1. Use robots.txt as a Starting Point
Most legitimate bots follow robots.txt, making it a reliable first step:
2. Confirm a Bot’s Identity Before Granting Trust
Not every bot is what it claims to be. Malicious actors often spoof user-agent strings to appear legitimate.
3. Monitor Bot Traffic as Carefully as Human Traffic
Many analytics tools filter out bot activity by default, but bots still interact with your infrastructure and data.
Bot Management solutions like HUMAN surface bot activity in dashboards and detailed bot profiles, making it easier to understand which bots are interacting with your site and how.
4. Apply Tiered Controls Based on Purpose
Not all bots should be treated the same. Match your response to their intent and impact.
5. Revisit and Adjust Bot Policies Regularly
Bot ecosystems evolve rapidly, especially with the rise of AI agents and data harvesters.
Best Practices for Managing AI Agents and Agentic Browsers
AI agents and agentic browsers should be treated as user-directed automation, not traditional “bots.” Because many agentic clients present as standard Chromium traffic, user-agent and robots.txt controls are not a reliable management layer on their own.
Managing Agentic Traffic with HUMAN AgenticTrust
Agentic browsing is already reshaping how users research and buy; the question is whether you can see agentic sessions clearly and control what they are allowed to do. AgenticTrust is positioned to classify agentic sessions, apply granular permissions (read vs login/checkout), and enforce those policies in real time—so beneficial automation can proceed while risky actions are contained.
Ready to manage AI agents and agentic browsers on your terms? Request a demo to learn how AgenticTrust turns agent activity into trusted engagement.
Take Control of Your Bot Traffic with HUMAN
The above best practices provide a foundation, but managing bots effectively at scale requires visibility, precision, and adaptability.
HUMAN helps organizations enforce bot access policies with greater accuracy and less manual overhead. From verifying the identity of search engine crawlers, to detecting obfuscated AI agents, to blocking unwanted scraping traffic before it reaches your application, HUMAN gives security and engineering teams the tools they need to stay in control.
With HUMAN, you can:
Managing bots shouldn’t require guesswork or compromise. HUMAN makes it easy to welcome the bots you want and block or monetize the ones you don’t.
If you’re ready to go beyond basic detection and take control of your automated traffic, get in touch with our team for a demo or learn more about how HUMAN defends the entire user-lifecycle.
Grow with Confidence
HUMAN Sightline protects every touchpoint in your customer journey. Stop bots and abuse while keeping real users flowing through without added friction.